(Créditos para Gustavo Pinheiro e Leandro Lima)
1. Introdução:U
m device driver é um módulo carregável do kernel que gerencia a transferência de dados entre um dispositivo e o sistema operacional. Módulos carregáveis são carregados no momento do boot, ou por pedidos e são descarregados por pedidos. Um device driver é uma coleção de rotinas em C e estruturas de dados que podem ser acessados por outros módulos do kernel. Essas rotinas devem usar interfaces padrão chamadas de pontos de entrada. Pelo uso de pontos de entrada, os módulos requisitantes ficam isolados dos detalhes internos do driver. Esses componentes são muito importantes, pois tornam a programação muito mais simples, assumindo a responsabilidade por tratar com as complexidades de cada dispositivo instalado. Os drivers atuam basicamente como atores entre o dispositivo e o aplicativo ou o sistema operacional que o utiliza. O código de alto nível pode ser escrito indepedentemente dos hardwares controlados. Cada versão de um dispositivo, como impressoras, requerem comandos especializados. Por outro lado, a maioria dos aplicativos acessam os dispositivos (como ao enviar um arquivo para a impressora) utilizando comandos de alto nível (por exemplo, println). O driver aceita essas sentenças genéricas e as convertem em comandos de baixo nível que o dispositivo possa entender.
Sem esses drivers, o computador não consegue estabelecer nenhuma comunicação externa, através dos dipositivos nele instalados. Não haveria maneiras de entrar com dados, nem de lê-los. Dentro do kernel do Linux, os device drivers ocupam uma parte bastante significativa. Assim como em outras partes do sistema operacional, eles devem operar em ambientes com alto nível de privilégio. Por isso, muito cuidado deve ser tomado ao programá-los.
Os device drivers para Linux são gerenciados pelo próprio kernel. Os módulos aqui trabalham como device drivers. Os módulos podem interagir com kernels diretamente. Quando desenvolvemos device drivers, utilizamos a estrutura de módulos para especificar rotinas personalizadas.
Para carregar o driver, usamos module_init e para descarregar, usamos module_exit. Quando module_init é executado, a primeira rotina também é executada. O kernel registra os drivers usando uma rotina de registro register_chrdev ao carregar o módulo, e ao descarregar o módulo usa unregister_chrdev. Isso funciona para dispositivos de caracteres.
No Linux, dispositivos são rotulados por números (0-255). Esses 256 números são conhecidos por números maiores. Um número maior é atribuído a um dispsositivo em particular. Com isso, o Linx pode manipular 256 dispositivos de uma vez (dispositivos maiores). Cada dispositivo maior pode manipular mais 256 dispositivos adicionais de seu tipo (o total fica em 256x256=65535). O arquivo documentation/devices.txt deve possuir a lista de todos os dispositivos maiores.
Os aplicativos não podem acessar o dispositivo pelo número maior diretamente. Em vez disso, eles usam as entradas do sistema de arquivos. Um ponto forte do Linux é que ele pode tratar todos os dispositivos físicos, dispositivos virtuais e sistemas de arquivos reais como sistemas de arquivos. Isso nos possibilita utilizar uma estrutura genérica para todos eles, sem precisar saber que tipo de dispositivo estamos usando. Todos os pontos de entrada de drivers estão localizados num diretório /dev. Por exemplo, /dev/tty1 é a porta serial 1 (COM1). Aplicativos que quiserem usar um driver, utilizam uma chamada de sistema para conseguir o manipulador do dispositivo. Uma vez que consegue o manipulador, ele ganha acesso aos dispositivos e pode usar o dispositivo pelas outras chamadas de sistema.

Figura 1 – Esquema de hardware/software
2. Requisitos: As principais características de um driver são:
- Executar gerenciamento de I/O
- Prover gerenciamento de dispositivos transparente, evitando programação de baixo nível (ports).
- Aumentar a velocidade de I/O, porque normalmente ela já é otimizada.
- Incluir gerenciamento de erro para hardware e software. - Permitir o acesso concorrente aos diversos processos de hardware.
Há 4 tipos de drivers: character drivers, block drivers, terminal drivers e streams.
Character drivers transmitem informação do usuário para o dispositivo (e vice-versa) byte por byte (figura 2). Dois exemplos são a impressora,
/dev/lp, e a memória (também é dispositivo),
/dev/mem.

Figura 2 - Character Drivers
Block drivers (figura 3) transmitem informação bloco por bloco. Isso significa que os dados que chegam (do usuário ou do dispositivo) são armazenados num buffer até que o buffer se encha. Quando isso ocorre, o conteúdo do buffer é fisicamente enviado ao dispositivo ou ao usuário. Essa é a razão pela qual todas as mensagens impressas não aparecem na tela quando um programa trava (as mensagens no buffer são perdidas), ou a luz do disquete nem sempre acende quando o usuário escreve em um arquivo. Os exemplos mais claros desse tipo de driver são discos: disquetes (/dev/fd0), discos rígidos IDE (/dev/hda) e discos rígidos SCSI (/dev/sd1).

Figura 3 - Block Drivers
Terminals drivers (figura 4) constituem um conjunto especial de character drivers para comunicação do usuário. Por exemplo, ferramentas de comando em um ambiente de janelas abertas, um terminal X ou um console são dispositivos que requerem funções especiais, por exemplo, as setas para cima e para baixo para um gerenciador de buffer de comando ou procedimentos especiais para drivers de tabulações, para lidar com todas as características especiais.
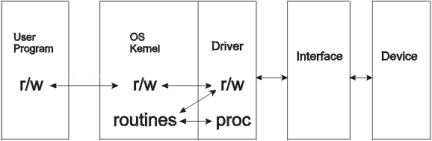 Figura 4 - Terminal Drivers
Figura 4 - Terminal Drivers
Streams são os drivers mais novos (figura 5) e são projetados para fluxo de dados de velocidades muito altas. Ambos o kernel e o driver incluem diversas camadas de protocolos. O melhor exemplo desse tipo é um network driver.
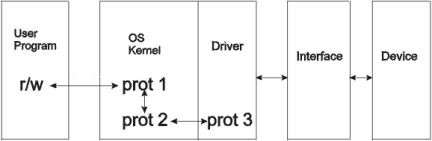 Figura 5 - Stream Drivers
Figura 5 - Stream Drivers
Como foi dito, um driver é uma parte de um programa. Ele é composto por um conjunto de funções em C, algumas das quais obrigatórias. Por exemplo, para um dispositivo de impressão, algumas funções típicas somente chamadas pelo kernel podem ser:
lp_init(): Inicializa o driver e é chamada apenas no momento do boot.
lp_open(): Abre uma conexão com o dispositivo.
lp_read(): Lê a partir do dispositivo.
lp_write(): Escreve no dispositivo.
lp_ioctl(): Executa operações de configuração de dispositivo.
lp_release(): Interrompe a conexão com o dispositivo.
lp_irqhandler(): Funções específicas chamadas pelo dispositivo para manipular interrupções.
Algumas funções adicionais estão disponíveis para alguns aplicativos, como *_lseek(), *_readdir(), *_select() e *_mmap().
3. Ferramentas:Para se desenvolver device drivers no Linux, é necessário possuir um conhecimento de:
Programação em C. É necessário ter conhecimento profundo dessa linguagem, notadamente no que diz respeito ao manuseio de ponteiros e manipulação de funções.
Microprogramação. É necessário saber como os microcomputadores funcionam internamente (endereçamento de memória, interrupções, etc). Todos esses conceitos devem ser familiares para um programador de assembly.
4. Desenvolvimento:
O kernel do Linux suporta dois principais tipos principais de drivers USB: drivers em sistema host e drivers em um dispositivo. Os drivers USB para um sistema host controlam os dispositivos USB em que são conectados, pelo ponto de vista do host (um host USB comum é um computador desktop). Os drivers USB, num dispositivo, controlam como aquele dispositivo é visto pelo computador host como um dispositivo USB. Como o termo ”USB device drivers” é um pouco confuso, os desenvolvedores USB criaram o termo “USB gadget drivers” para descrever os drivers que controlam um dispositivo USB que se conecta a um computador. Os drivers USB residem entre os diferentes subsistemas do kernel (block, net, char, ...) e os controladores de hardware USB. O USB core fornece uma interface para drivers USB utilizarem e controlar o hardware USB, sem se preocupar com os diferentes tipos de controladores de hardware USB presentes no sistema.
Desenvolvendo um Driver USB
A abordagem para se desenvolver um driver USB é similar à de um PCI: o driver registra seus objetos com o subsistema USB e depois usa identificadores da marca e do dispositivo para dizer se seu hardware foi instalado.
Dispositivos suportados pelo driver
A estrututura da struct usb_device_id fornece uma lista de diferentes tipos de dispositivos USB que este driver suporta. A lista é usada pelo USB core para decidir a qual driver deve fornecer um dispositivo, e, pelos scripts hotplug, decidir que driver carregar automaticamente quando um dipositivo específico é conectado ao sistema.
A estrututura struct usb_device_id é definida com os seguintes campos:
__u16 match_flags
Determina qual dos campos a seguir na estrutura o dipositivo deve ser correlacionado. Esse é um campo pequeno definido pelos valores USB_DEVICE_ID_MATCH_* especificados no arquivo include/linux/mod_devicetable.h. Esse campo normalmente não é diretamente definido, mas é inicializado pelas macros do tipo USB_DEVICE definidas posteriormente.
__u16 idVendor
A ID USB da marca para o dispositivo. Este número é atribuído pelo fórum USB aos seus membros e não pode ser criado por mais ninguém.
__u16 idProduct
A ID USB do produto para o dispositivo. Todas as marcas que possuem uma ID de marca atribuída a eles podem gerenciar suas IDs de produtos de qualquer modo que escolherem.
__u16 bcdDevice_lo __u16 bcdDevice_hi
Definem os finais inferior e superior da extensão de todos números da versão dos produtos atribuídos a uma marca. O valor bcdDevice_hi é inclusivo; seu valor é o número do dipositivo com a maior numeração. Ambos esses valores são expressos na forma decimal de codificação binária (BCD). Essas variáveis, combinadas com o idVendor e o idProduct, são usadas para definir uma versão específica do dispositivo.
__u8 bDeviceClass __u8 bDeviceSubClass __u8 bDeviceProtocol
Definem a classe, a subclasse e o protocolo do dispositivo, respectivamente. Esses números são atribuídos pelo fórum USB e são definidos na especificação USB. Esses valores especificam o comportamento de todo o dispositivo, incluindo todas as interfaces nesse dispositivo.
__u8 bInterfaceClass __u8 bInterfaceSubClass __u8 bInterfaceProtocol
Assim como os valores específicos dos dispositivos citados acima, esses definem a classe, a subclasse e o protocolo da interface individual, respectivamente. Esses números são atribuídos pelo fórum USB e são definidos na especificação USB.
kernel_ulong_t driver_info
Esse valor não é usado para ser correlacionado, mas ele carrega a informação que o driver pode usar para diferenciar os dispositivos entre si na função probe de chamada ao driver USB. Assim como com os dispositivos PCI, há muitas macros que são utilizadas para iniciallizar essa estrutura:
USB_DEVICE(vendor, product)
Cria uma struct usb_device que pode ser usada para correlacionar somente os valores da ID do produto e da marca específica.
USB_DEVICE_VER(vendor, product, lo, hi)
Cria uma struct usb_device que pode ser usada para correlacionar somente os valores da ID do produto e da marca específica dentro do escopo da versão.
USB_DEVICE_INFO(class, subclass, protocol)
Cria uma struct usb_device que pode ser usada para correlacionar uma classe específica de dispositivos USB.
USB_INTERFACE_INFO(class, subclass, protocol)
Cria uma struct usb_device que pode ser usada para correlacionar uma classe específica de interfaces USB. Assim, para um simples driver USB que controla um único dispositivo USB de uma marca única, a tabela da struct usb_device_id fica definida como:
/* tabela de dispositivos que funcionam com esse driver */ static struct usb_device_id skel_table [ ] = { { USB_DEVICE(USB_SKEL_VENDOR_ID, USB_SKEL_PRODUCT_ID) }, { } /* Entrada para finalização */ }; MODULE_DEVICE_TABLE (usb, skel_table); Assim como com um driver PCI, a macro MODULE_DEVICE_TABLE é necessária para permitir que as ferramentas do espaço do usuário descubram quais dispositivos esse driver pode controlar. Mas para drivers USB, a string usb deve ser o primeiro valor na macro.
5. Instalação:
A instalação de drivers varia conforme a distribuição do Linux. O Linux usa módulos como device drivers. Todos os drivers estão instalados como módulos e localizados num diretório “/lib/modules/kernel_x.x.xx”. Um arquivo de configuração localizado em /etc/modules.conf é utilizado pelo kernel (e pelo usuário se você quiser substituí-lo) para carregar e descarregar módulos. A instalação e desinstalação de módulos pode ser feita por utilitários de módulo do kernel como insmod, rmmod e modprobe. Inserir e instalar um módulo não é tudo. O módulo tem que estar registrado como uma entrada de dispositivo no diretório /dev. O utilitário mknod reliza essa tarefa.
6. Testes:
Para testar os drives, deve-se entender de teste de softwares. Contudo, os drivers estão numa classe especial de software, porque eles podem mais livremente acessar recursos de baixo-nível do sistema do que qualquer outro aplicativo. Deve-se ter cuidado quando se criar um plano de testes e desenvolver testes de drivers, porque se um teste falhar, o sistema pode parar de responder.
** Estratégias de Testes Estratégias para testar drivers podem ser geralmente categorizadas nas seguintes áreas:
- Use automação sempre que possível para detectar a maioria dos bugs.
- Teste cedo para detectar bugs de desenvolvimento durante essa fase.
- Use uma combinação de configurações gerais e de dispositivos.
- Use testes de equivalência, como agrupar drivers em classes e testar essa classe.
- Rode testes de estresse junto com testes de sistema.
- Incorpore aspectos que são específicos ao subsistema do driver, não ao do software aplicativo, em testes funcionais.
- Use recursos de testes já estabelecidos e teste o framework em si.
- Execute testes de integração e de cenários baseados em dados do cliente que utilizam a mesma classe de drivers.
** Metodologias de Testes Os métodos a seguir são tipicamente usados para testar device drivers:
* Análise Estática
Um driver é um programa de software, e, como qualquer outro programa, o código-fonte deve ser testado por várias ferramentas diferentes de verificação e de análise para encontrar defeitos no código durante o desenvolvimento. A análise estática pode ser conduzida por ferramentas específicas que detectam certas classes de erros que não são detectadas por um compilador, como checar pelo nível correto de requisição de interrupção.
Testadores e Desenvolvedores de testes utilizam ferramentas que, a partir de um driver estabelecido em um estado instável, testa sistematicamente todos os code paths procurando por violações em regras específicas (pacotes de requição de I/O, níveis de requisição de interrupções, gerenciamento de energia, etc.). A análise em tempo real e as ferramentas de depuração são úteis quando o driver está executando uma operação.
* Testes Funcionais Os testes funcionais se aplicam a qualquer software. Para drivers, esses testes incluem a avaliação se o comportamento do driver segue a documentação de projeto para esse driver. Rodam-se testes funcionais sob condições regulares em um dispositivo de teste isolado que contém o driver e está minimamente configurado ou customizado. Deve-se começar os testes funcionais durante a fase de desenvolvimento assim que driver for utilizável e estiver estável o suficiente. Pode-se utilizar esses testes repetidamente durante as fases subsequentes do teste e do desenvolvimento do driver.
* Testes de Configurações Um driver pode se comportar se maneira distinta em diferentes configurações. Portanto, devem-se conduzir testes em vários tipos de ambientes e fazer dos testes de configurações uma parte da aprovação do teste regular. Testes de configuração incluem mudanças de configuração do sistema, mudanças no ambiente do sistema e mudanças nas configurações de dispositivos:
- Configuração de sistema: Teste o driver e diversas plataformas diferentes como x86, x64, dispositivos de multiprocessador e multicore com chipsets diferentes e builds checados.
- Ambientes de Sistema: Teste o driver com diferentes configurações de memória, de pouca a muita memória. Este teste pode gerar erros inesperados que não se detectariam de outra forma. Outro teste bom é aumentar a utilização da CPU de outro programa enquanto testa o driver. Este teste frequentemente gera bugs de timing.
- Configurações de dispositivos: Teste o driver com diferentes configurações de dispositivos, desde opções default ate opções raramente usadas. As opções menos usadas podem gerar erros inesperados, porque essa área geralente recebe pouca atenção durante o desenvolvimento. Se o dipositivo utiliza recursos de hardware, a matriz de testes deve incluir mudanças de teste nesses recursos. O teste de compatibilidade de harware também é importante. Esse teste consiste em se testar o driver e diversos dispositivos que utilizam diferentes tipos de conexão, como PCI e PCI-Extender (se o harware for baseado em PCI).
* Teste de Integração e de Cenário Testes de cenário são ótimos para testar qualquer software, quer seja um software aplicativo, um banco de dados ou um driver. De dados históricos do cliente, pode-se geralmente inferir como o driver será utilizado pelo cliente, e tais cenários devem ser testados. Testar o comportamento funcional e usar automação são um ótimas maneiras de encontrar bugs. Contudo, a maioria do erros inesperados são encontrados por testes de integração e de cenário.
Testes de integração também simulam o ambiente do usuário em alguns casos. Por exemplo, a maioria dos clientes se logam como um usuário (em vez de com permissões de administrador) e instalam algum software. Testar o driver em um ambiente que simula esse cenário pode encontrar bugs que não seriam encontrados durante a verificação funcional típica.
* Testes de estresse O objetivo de testes de estresse é colocar o driver em um ambiente com condições altas ou inesperadas de sobrecarga. Testar o estresse de drivers é muito importante. Ele é executado utilizando repetidamente as mesmas funções para encontrar falhas no sistema e vazamentos na memória. Testes de estresse são úteis quando rodados em combinação com a alta utilização da CPU por algum outro software.
* Testes Longos Ocasionalmente, testadores e desenvolvedores confudem testes longos com testes de estresse. O objetivo dos testes longos é simular como um driver é utilizado numa base diária no ambiente do usuário final. Testes longos rodam aplicativos por períodos longos de tempo enquanto aplicam uma carga de driver típica. Esses testes encontram bugs difíceis de se encontrar que são relacionados com o timing e que não seriam descobertos pelos testes típicos.
* Testes de privilégios Como os drivers possuem altos privilégios para acessar recursos de sistema, devem-se testá-los em formas diferentes das da maioria dos aplicativos. Esses testes adicionais incluem:
- Testes de memória
- Testes de cancelamento de I/O
- Testes de setup
- Testes de gerenciamento de energia
- Testes de penetração
- Testes de segurança
7. Referências:http://www.linuxjournal.com/article/2476
http://www.lrr.in.tum.de/Par/arch/usb/usbdoc/node14.html
http://learningdevicedrivers.blogspot.com/
http://www.ddj.com/linux-open-source/